


Viewing G2’s AI War- Mirae Asset Securities
Closed-Source America vs. Open-Source China


1. The Dawn of Digital Mercantilism
(1) “Software Swallows the World”
On March 11, President Donald Trump held an event on the south lawn of the White House to showcase Tesla vehicles. During the event, while sitting in the driver’s seat of a red Tesla Model S and experiencing the car’s cutting‐edge technology, President Trump famously exclaimed, “Wow… everything’s computer!” This remark appeared to capture his astonishment at encountering, for the first time, the digital control panels and computer-based functionalities of electric and self-driving vehicles. Notably, Elon Musk was seated in the front passenger seat at that time.
Historically, President Trump did not seem particularly tech-savvy; he tended to favor a pen over email and even once asked, “What is digital?” In this context, for the leader of the world’s most powerful nation to declare that everything is driven by computers carries significant meaning.
This simple remark quickly went viral on social media, becoming a “meme” due to its brevity yet potent impact. Much like the iconic lines from the film Lawrence of Arabia, where great achievements often stem from modest beginnings, this statement resonates deeply. For reference, in the film, Lawrence reevaluated the nature of warfare to achieve maximum impact with limited resources and even remarked, “Foreigners always come to teach, but it is far better to learn.” It is believed that Trump—born during the Baby Boomer era—came to understand that computer software is the essence of modern warfare after encountering the “outsider” Elon Musk.
Thus, Trump’s remark was more than enough to boost the morale of many software developers. Palmer Luckey, CEO of Anduril—one of the leading companies driving the convergence of AI and defense—interpreted Trump’s words as, “In short, software is swallowing the world.” This phrase was originally coined by Mark Andreessen, the founder of Andreessen Horowitz, America’s most renowned venture capital firm, in 2011, and it has since become something of a manifesto for Silicon Valley.
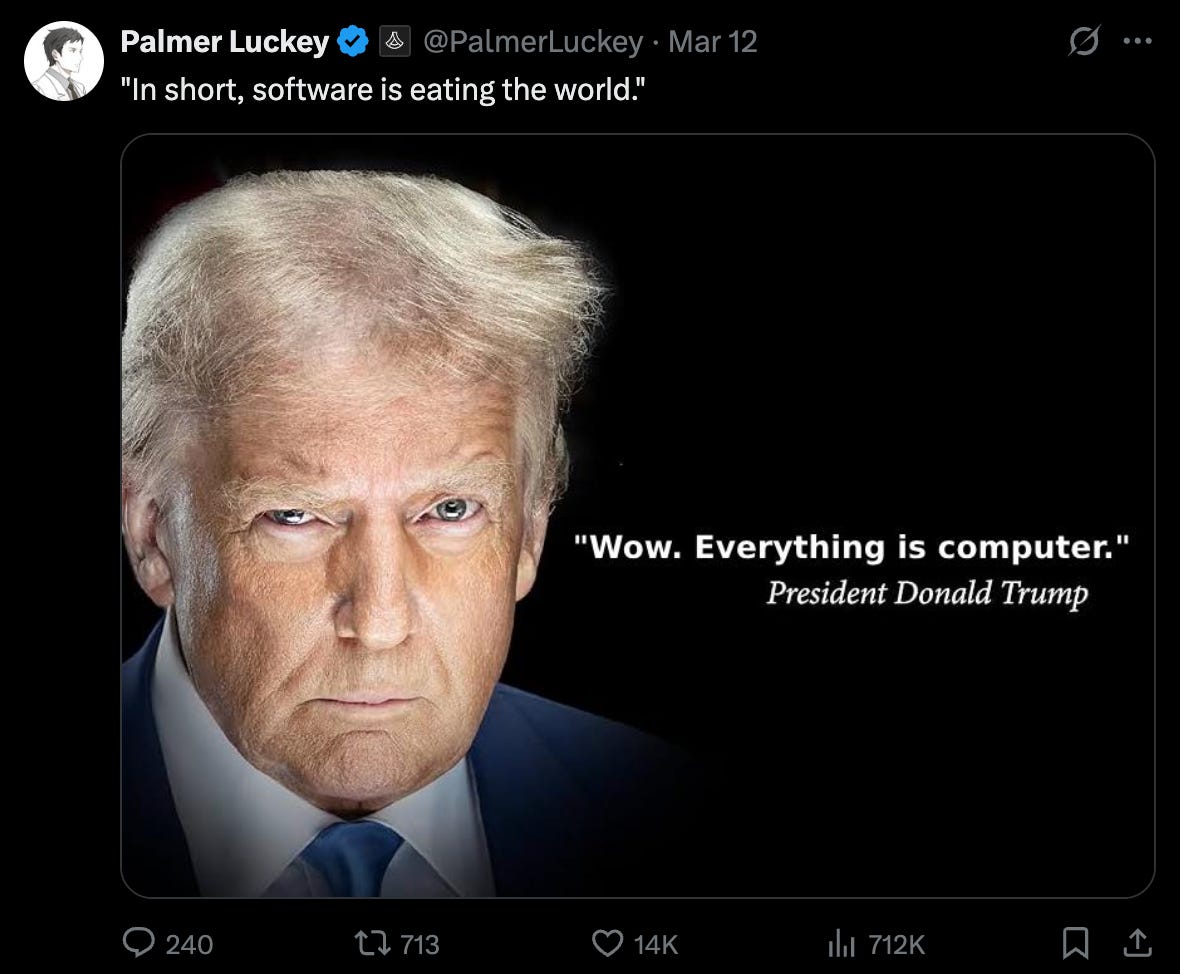
Andreessen predicted that software companies would come to dominate vast sectors of the economy and upend traditional industrial structures. Over time, the San Francisco mindset has successfully permeated even Washington D.C. In light of the Trump administration’s policy orientation, which is expected to drive innovation centered around software and the computers that run it, this development carries profound significance. And today, the most prominent technology representing modern computer software is AI. In other words, Trump is expected to relentlessly pursue solutions through AI technology in order to revive the mercantilist golden age of the United States reminiscent of the era of President William McKinley, whom he greatly admires.
(2) China’s Transition to Soft Power and America’s Efforts to Maintain Technological Superiority
In fact, AI has emerged as the most critical issue in international diplomacy. As frequently mentioned in AI Weekly, AI is an asymmetric power with destructive capabilities akin to those of nuclear weapons. In the future, more and more national leaders will likely refer to AI ad nauseam.
Moreover, because of its escalating importance, the myriad of complex issues in international diplomacy may eventually be unraveled by the singular thread of AI. For example, French President Emmanuel Macron has stated that without state-led investments—including in AI—Europe could perish. He did not merely suggest that Europe would suffer; he asserted that such investments are a matter of life or death.
On March 8, 2000, President Bill Clinton, speaking at Johns Hopkins University, mentioned an attempt by China to control the internet. At that time, Clinton remarked, “Good luck! It’s like nailing jelly to a wall!” This sarcastic comment was made in response to China’s initiation of building its internet censorship system—the Great Firewall (also known as the “Golden Shield Project”)—in the late 1990s. Clinton’s famous remark reflected the prevailing Western belief that, given the inherently free nature of the internet, China’s efforts at technological control and social experimentation on the web would be futile.
In 1998, the “Golden Shield Project” was launched, laying the groundwork for the system later known as the “Great Firewall.” The project aimed to establish a technical infrastructure that would filter internet content, block IP addresses and domain names, and inspect data.
Ironically, through nearly 20 years of relentless effort, China has almost succeeded in “nailing jelly to a wall.” And as we now enter the era of the AI revolution following the internet revolution, China’s stance has undergone a complete 180-degree turnaround.
On March 7, 2025, during a press conference held in the course of the 3rd session of the 14th National People’s Congress, Foreign Minister Wang Yi stated, “Science and technology should not serve as tools to erect an iron curtain; rather, they must become a common asset to be shared universally.” Wang asserted that China’s technology is breaking through the bounds of people’s imagination—where there is blockade, breakthroughs occur; where there is pressure, innovation thrives. It is as if a frog has forgotten its tadpole days, exuding an air of overconfidence. Yet, this also signifies a strong, well-founded confidence in technology and innovation.
Subsequently, Wang spoke extensively about various technologies—particularly AI—among topics such as quantum computing and 5G. He referred to Xi Jinping’s AI Global Initiative, noting that China has decided to open up its AI technologies to Global South nations, including countries in Brazil and Africa.
In Other Words, China Is Now Intending to Utilize AI Technology as an Important Tool for International Cooperation and Diplomacy.
To that end, it can be said that China is advocating for the development of AI in an open-source format. Recently, China has abandoned its belligerent, blustering diplomatic style toward other nations and is instead emphasizing soft power. This is because a belligerent approach does not suit a strategy aimed at becoming a major exporter of AI technology—and at the center of AI governance—to neighboring countries and, more broadly, to the BRICS+ nations. Consequently, it appears that the Chinese Communist Party is actively promoting and emphasizing the philosophy of open source. We also believe that many second-generation DeepSeek-like companies will emerge in the future, delivering a cascading “Deep Impact.” Moreover, the rapid proliferation of small, agile AI startups competing in open-source development is likely viewed by the Chinese government as easier to control. Of course, when Alibaba’s Jack Ma was “given a technical lottery,” it was less about making a lot of money with AI and more about thrusting upon him the challenge of establishing global leadership in the coming AGI era. It is presumed that “national rejuvenation”, a key component of “Xi Jinping Thought,” will hold just as much importance in the realm of AI.
")
Conversely, the United States is expected to repeatedly underscore the risks of open source, thereby dampening the atmosphere and raising caution.
In particular, it will emphasize that open source represents a potential runaway locomotive toward a dystopia of “state-controlled AI”—a description aimed squarely at China. Internally, however, the U.S. will face mounting pressure to accelerate the development of cutting-edge closed-source technologies. This, of course, implies the need for greater computing resources and increased energy consumption.
It is indeed a fascinating paradox that authoritarian regimes champion open source while liberal democracies lean toward closed-source models. Of course, both the U.S. and China must exercise caution regarding open source and monitor the misuse of closed models. This is not a matter of right or wrong but rather a competitive strategy based on each side’s value judgments.
Furthermore, one of the major economic phenomena observed recently is the collapse of the concept of “comparative advantage.”
China has dominated all sectors—from light industries to high-tech fields—thereby absorbing economic opportunities from other countries, including the United States. The U.S. pressuring TSMC in Taiwan is a case in point that reflects Washington’s impatience in securing a comparative advantage. When one considers this harsh reality in conjunction with Trump’s remark that “everything’s computer,” it becomes clear that software and AI are poised to be the core components of Trump’s mercantilist statecraft. The notion that software is the one comparative advantage that must be absolutely safeguarded in relation to China has been stressed by Palantir CEO Alex Karp for several years now.
AI has become the focal point of all discussions, and it represents the endgame of global hegemony, where every resource and capability is mobilized. While the dot-com era was characterized by U.S.-led unipolarity, the current period is the era of “Yalta 2.0.” Our team believes that although there are similarities with the internet bubble, the situation is fundamentally different—the cost of lagging behind will be far too severe.
“Yalta 2.0” is a modern analogy to the 1945 Yalta Conference among the U.S., U.K., and the Soviet Union:
• Xi Jinping and Roosevelt (U.S.): China is seeking to expand its global influence through initiatives like the Belt and Road and proposals for peacekeeping in Ukraine. This is reminiscent of how Roosevelt led the world order by establishing the United Nations and the Bretton Woods system. In this context, Xi Jinping appears to be signaling an intention to form a new world order together with Trump and Putin.
• Putin and Stalin (Soviet Union): With the invasion of Ukraine and increased influence over former Soviet states, Putin’s actions resemble those of Stalin’s era.
• Trump and Churchill (U.K.): Trump’s “America First” policy could lead to a reduction in international commitments and a retreat in leadership, positioning the U.S. similarly to Britain during Churchill’s time, which was not seen as a dominant leader among its allies.
(3) The “Rhythm” of Technocracy: Lessons from the Dot-Com Bubble and the Massive Investments by Big Tech
“History doesn’t repeat itself, but it often rhymes.” – Mark Twain
Just as the collapse of tech stocks during the dot-com bubble was precipitous—Amazon (AMZN) fell from $113 to $6 between 2000 and 2003, a drop of over 90%—there have been many doubting glances cast at whether AI will be any different.
Yet, in retrospect, Amazon emerged as the clear winner of the internet era, growing 400-fold thereafter. Our team is not sure if the trajectory of AI stocks will follow the same rhythm as the dot-com bubble, but we do believe in the market’s “learning effect.”
Moreover, the pace of AI development is increasingly compressed, and the speed of innovation is accelerating. In other words, while market shocks are inevitable, the lessons of past eras—and the tremendous value of the crown that the victor of the AI era will hold—make the future seem more promising.
Even among the Big Tech companies that are in the most advantageous positions, a continuous trend of increased investment is being observed. On March 12, at CERA Week 2025 in Houston, Texas, Amazon, Google, and Meta signed a pledge to triple the world’s nuclear energy capacity by 2050. Currently, the global nuclear capacity stands at 377GW generated by 417 operating reactors, with a goal to expand this to 1,131GW by 2050. This pledge, led by the World Nuclear Association, is significant in that major companies outside the nuclear industry are publicly backing a large-scale expansion of nuclear power for the first time.
It is not just nuclear power: the demand for energy for AI has rekindled interest in natural gas, which is somewhat “less environmentally friendly.” Microsoft has stated that it may use natural gas to supply power to its AI data centers in order to keep up with energy demand—effectively sidelining ESG policies in favor of AI.
Meanwhile, Elon Musk’s xAI recently acquired a 1-million-square-foot facility in Memphis to bolster its AI data center presence.
Additionally, Amazon CEO Andy Jassy remarked, “In our AWS business, generative AI is already a multi-billion-dollar enterprise growing by triple-digit percentages year over year. But if we have more capacity, we can monetize it further.” This indicates that, given the business’s growth—doubling annually—Amazon will purchase AI chips whenever the opportunity arises.
Furthermore, Oracle co-founder and CTO Larry Ellison stated, “The Oracle Database MultiCloud revenue from the three major CSPs has increased by 92% in just the past three months. GPU consumption for AI training has surged by 244% over the last 12 months.” Unlike Microsoft’s somewhat subdued recent tone, there appears to be little room for any slowdown in investment.
“Database MultiCloud” refers to Oracle’s strategy of offering its database technology to other major cloud service providers (such as Microsoft, Google, and Amazon) so that they can run Oracle databases on their own cloud platforms—for example, enabling Oracle DB to run on Amazon AWS or Google Cloud.
It was recently reported that TSMC’s chip plant in Arizona, USA, has already sold all of its production capacity through late 2027, to meet the demands of major U.S. customers like Apple, AMD, Qualcomm, Nvidia, and Broadcom.
Among Big Tech, one of the most surprising bets recently is being made by Google. Reports indicate that Google currently owns a 14% stake in Anthropic and has invested over $3 billion in total. For reference, Anthropic recently raised $3.5 billion in a funding round, which valued the company at $61.5 billion and brought its total fundraising to $14.8 billion. Out of this, Google’s total investment amounts to $3 billion, while Amazon’s is approximately $8 billion.
This information comes from court documents obtained by The New York Times, and it is the first time the exact 14% stake has been publicly disclosed. According to the documents, Google is limited to holding a maximum of 15% of Anthropic’s equity, meaning it has essentially done the best it can under these constraints.
With its in-house language model, Gemini, and its competition with OpenAI and xAI on frontier-level performance, Google’s bet is highly significant. By investing in emerging AI companies, Google is positioning itself to profit regardless of the direction the market takes. Whether it develops AI technology directly or invests in promising startups, it is a sign of the urgency to become a winner.
2. U.S. Comprehensive Containment Measures
(1) OpenAI’s Plea: “Don’t Use DeepSeek”
The U.S. sense of urgency is not only evident in its investments but also in its containment efforts. On March 13, 2025, Chris Lehane, OpenAI’s Global Head of Operations, submitted a 15-page letter to the White House Office of Science and Technology Policy. According to the document, DeepSeek’s models (including the R1 inference model) are deemed unsafe because, under Chinese law, they would be required to provide user data to the Chinese government.

In fact, according to DeepSeek’s privacy policy, users’ personal information is stored on secure servers located in the People’s Republic of China. Furthermore, OpenAI has emphasized that Chinese AI developers (including those at DeepSeek) have unrestricted access to all data—even copyrighted material—whereas American companies are constrained by the fair use principle. They went so far as to claim that if this imbalance continues, “the AI race will effectively be over.” This clearly indicates that China’s AI development is being perceived as a geopolitical threat.
Meanwhile, the Chinese government has begun to regard DeepSeek as a “national treasure” and is significantly tightening its control and oversight over the company. For example, the government has required some DeepSeek employees to submit their passports, effectively preventing the overseas movement of key technical personnel. Citing these facts, OpenAI has argued that DeepSeek is “a company receiving state subsidies and controlled by the state” and has even requested that the U.S. government impose sanctions on it. Moreover, in the export rules issued by the Biden administration last January, it was stated that in all countries classified as “Tier 1,” the use of Chinese-made models must be banned to prevent the risk of IP theft—essentially seeking to split the AI industry into a “U.S. camp versus Chinese camp.” This scenario has been forecast several times by AI Weekly. In this way, AI and international relations are very much “aligned.”
(2) CSIS’s Huawei Report
On March 7, the renowned U.S. think tank, the Center for Strategic and International Studies (CSIS), released a report on Huawei. Authored by Gregory C. Allen, the report enumerated numerous insightful pieces of information about China’s AI drive, including details on Huawei and DeepSeek. He noted, first of all, that DeepSeek should not be dismissed as mere psychological warfare but is, in fact, a significant and noteworthy development.
More importantly, he emphasized two recent successes of Huawei. One was that TSMC was compelled to manufacture a large volume of Ascend (Huawei’s AI accelerator) chips, which were then imported via alternative channels. The other was that SMIC managed to smuggle semiconductor equipment to enable the production of advanced chips. In particular, he mentioned a long-term risk: the possibility that the Chinese open-source community might become interested in running the DeepSeek model on Huawei’s CANN (Compute Architecture for Neural Networks) platform, a move that could threaten Nvidia’s monopoly over the CUDA platform. Our team has similarly emphasized that Nvidia’s true competitive advantage lies not in its silicon, but in CUDA. Given that the comparative advantage the U.S. must absolutely preserve against China is in software, this issue will be closely monitored.
However, DeepSeek is currently not interested in Ascend chips, because, according to CSIS, Ascend still suffers from “abysmal chips and terrible supporting software.” Although it may take several more years for Huawei to build a software ecosystem to rival CUDA, it is also true that China is continuously catching up on the hardware front. Furthermore, the report stressed at length—quoting Taiwanese officials—that “Huawei, through a paper company, has bypassed U.S. sanctions to secure over 2 million AI semiconductor units from TSMC.” This refers to the fact that while TSMC manufactured Ascend 910B logic dies, Huawei was able to access TSMC’s advanced node manufacturing capabilities via a paper company. Huawei, of course, countered by stating that “no chips have been produced through TSMC since the implementation of the FDPR amendment by the U.S. Department of Commerce in 2020.” Strictly speaking, not ordering the chips directly but importing them through a third party constitutes a different matter. There is a significant possibility that third-party companies, such as China-based chip design firms Sophgo and Bitmain, willingly played the role of the paper company.
In October 2024, TSMC notified both the Taiwanese government and the U.S. Department of Commerce that chips produced by the company had been found in Huawei products. This occurrence is possible because the U.S. sanctions in question operate in a negative manner targeting only specific companies, and because they rely on easily manipulated “customer certifications” rather than physical verification—leaving many loopholes. Ultimately, since November last year, TSMC has ceased providing advanced chips below 7 nanometers to Chinese customers, including Sophgo. The key point is that Huawei has, albeit illegally, managed to secure 2 million dies of the Ascend 910B chip from TSMC.
Furthermore, as AI Weekly revealed some time ago, their reliable partner SMIC has already announced plans to produce 300,000 units of the 910B and 100,000 units of the 910C, respectively, using its own sub-7nm process. When combined with the 910B units produced last year, the total number of 910C chips produced and secured from SMIC amounts to 400,000 units. In addition, the necessary HBM2E memory has also been stockpiled from Samsung Electronics—even though this, too, is subject to control, it was secured beforehand. Combining what was received from TSMC with what was produced by SMIC will eventually yield enough to produce approximately 1.4 million 910C accelerators. This is an amount that cannot be ignored.

Then, the question that arises is how their computational performance compares to that of the United States. To address this, it is necessary to examine the information disclosed by Lennart Heim, a computer scientist at another renowned American think tank, the RAND Corporation.
The Ascend 910C is expected to achieve approximately 800 TFLOP/s in FP16 and around 3.2 TB/s of memory bandwidth. Despite utilizing 60% more logic die area, its performance is only about 80% of that of NVIDIA’s previous generation H100 (released in 2022). For reference, the H100 delivers roughly 1000 TFLOP/s in FP16 and 3.9 TB/s of memory bandwidth, with a die area of 814 mm².
Unlike NVIDIA’s advanced packaging used in its B100/200 series, the Ascend 910C is likely to employ a technically less sophisticated approach that uses two separate silicon interposers connected via an organic substrate. As illustrated in the diagram, each interposer houses one processor die and four HBM stacks. The 910B die measures 664 mm² each, and the two interposers are physically separated yet placed side by side on the organic substrate. The problem lies in the extended communication path between the dies: a signal must travel from the first die, pass through the first interposer to the organic substrate, then traverse the second interposer to reach the second die.
Furthermore, the wiring density on an organic substrate is significantly lower than that on a silicon interposer. While silicon interposers can support extremely fine wiring on the order of several micrometers, organic substrates are limited to thicker wiring on the order of tens of micrometers.
Due to these physical differences, the inter-die bandwidth could be 10–20 times lower than that of NVIDIA’s solution. If the bandwidth is that low, the assembly is effectively not a single chip; rather, it must be treated as two connected accelerators.
In conclusion, while Huawei’s pursuit is formidable, the technological gap still appears to be quite significant. Compared to NVIDIA’s B200, which will be deployed in data centers this year, the RAND Corporation points out that the 910C offers roughly three times lower computational performance and about 2.5 times lower memory bandwidth (based on HBM2E; HBM3 is also a possibility), with much poorer power efficiency. Moreover, the Western bloc, including the United States, is expected to have at least five times as many chips and 10–20 times the computing power this year, meaning that overall, the United States maintains a strong computational advantage.
Assuming that each Ascend 910C chip performs at 80% of an H100, 1.4 million units of 910C chips would be equivalent to roughly 1.1 million H100 GPUs. What might happen if China were to centralize these chips?
It could result in an enormous cluster comparable to the next version of Colossus envisioned by xAI or the Stargate project of the OpenAI consortium—an outcome that is deeply concerning. There is absolutely no room for complacency. Moreover, operating under an authoritarian regime, China exhibits unparalleled coordination and speed in policy implementation. This is a key point to monitor, as it suggests that China will gain competitiveness in many areas. If they succeed in creating a truly centralized cluster, it is not out of the question that they could develop a next-generation model capable of competing with GPT-6. In short, the AI competition between the United States and China is likely to intensify even more than it is today.
Nevertheless, it is a fact that the strengthened U.S. export controls implemented last January have made it extremely difficult to procure even several times as many chips. In this context, while developing individual AI models might be feasible, building large-scale infrastructure capable of simultaneously serving millions of users or numerous AI agents will face limitations.
China is still facing a significant chip shortage. When Huawei’s chairman and DeepSeek’s CEO, Liang Yuanpeng, each state that they are lacking computing power, they speak sincerely. The ‘panic buying’ of NVIDIA chips in China is likely to continue for the foreseeable future.
(3) Eric Schmidt’s New Paper
It appears that U.S. containment efforts will not end with export controls alone. Beyond government measures, voices of concern and warnings about AI development are increasingly emerging from the private sector. This time, former Google CEO Eric Schmidt—who once led the company during its heyday—has taken on this responsibility.
A few days ago, Schmidt, along with Alexander Wang (CEO of Scale AI) and Dan Hendrickx (Director of the AI Safety Center), published a paper titled “Superintelligence Strategy.” The paper argues that the development of superintelligence will intensify the power competition between nations and increase the risk of conflicts (potentially a third world war), thereby necessitating a strategic approach to mitigate such dangers. It defines superintelligence as an AI that is vastly superior to humans in nearly every cognitive task, and AI researchers have predicted that its emergence is not far off.
Notably, Schmidt proposed three strategies—deterrence, competitiveness, and non-proliferation. Among these, deterrence is the paper’s core argument, drawing a parallel to the Mutually Assured Destruction (MAD) strategy of the nuclear age, suggesting that a similar approach is required in the age of superintelligence.

The authors, including Eric Schmidt, introduced a new concept called MAIM (Mutual Assured AI Malfunction). They argued that if one nation monopolizes superintelligent AI for dangerous purposes such as military applications, other nations must preemptively engage in “sabotage” to thwart it. For instance, if one country attempts to dangerously monopolize AI, rival nations should be capable of impeding AI development through various means—blowing up data centers, obstructing researchers, launching cyberattacks, and more. This is an astonishing idea.
They noted, however, that clear communication is necessary to prevent such sabotage from escalating into full-scale war—a sentiment that somewhat echoes how Russia labels a war as a “special military operation.” Ultimately, it seems likely that a logic of power will prevail, hinting at a confrontation between the U.S. camp and the Chinese camp.
The purpose of MAIM is to delay the emergence of superintelligence and buy time to ensure safety. Rather than resorting to kinetic military force, MAIM aims to strengthen cyberattack capabilities to curb the AI development race. Under a MAIM regime, cyberattacks should be considered a routine means of restraint. Whether or not the MAIM system is accepted by the international community, it suggests that interest in cyberattacks and security may undergo even more dramatic changes than we see today.
Moreover, the MAIM strategy evokes similarities to the “Dark Forest” theory found in Liu Cixin’s science fiction trilogy, The Three-Body Problem.
The Dark Forest theory posits that the universe is like a dark forest filled with countless civilizations, and for survival, every civilization acts based on the following two assumptions:
1. Survival is the highest priority.
Every civilization strives to conceal itself as much as possible, remaining quietly hidden to avoid revealing its location.
2. The inability to discern another civilization’s intentions means that, upon discovery, the most rational strategy is to launch a preemptive strike.
If a civilization’s existence becomes known, there is a compelling imperative to attack first to eliminate the risk of being attacked.
Since superintelligence can be regarded as the “ultimate weapon,” Schmidt argues that it is strategically rational to prepare for the possibility that if another nation develops it before you do, its intentions might be malevolent. In other words, both assumptions justify a preemptive, implicit form of attack to prevent an adversary from gaining an upper hand, based on an “unstable balance” rather than stable peace. While this is certainly not an ideal solution, it may currently be one of the best strategies available.
(4) Why do such containment measures and concerns persist?
Recently, cautionary voices among AI experts have continued to emerge, driven by the belief that the era of an intelligence explosion is imminent. (The “recent” mentioned here refers to events within the last month and not a long-term trend.)
A nonprofit research organization called Forethought—supported by Open Philanthropy (a backer of OpenAI)—published an article titled “Preparing for the Intelligence Explosion” on March 11. The article emphasizes that there is a high likelihood that superintelligence will become a reality within the next ten years, so preparations must begin now.
Forethought posits that the advancements in science, technology, politics, and philosophy that took place over the 100 years from 1925 to 2025 will now be compressed into intervals of just ten years. By contrast, human decision-making capabilities are unlikely to keep pace, and existing institutions may not function properly—rendering humans the bottleneck.
Their reasoning for the accelerated pace of AI development is clear. The computational load used for training has increased roughly 4.5 times per year, and new algorithms have improved training efficiency by about threefold annually, achieving higher performance with the same amount of computation. Moreover, scaffolding techniques that enhance the capabilities of trained models—such as improved tool usage, better prompting, and synthetic data—have also improved threefold each year, while the computational load required for inference has decreased to one-tenth per year, even as the total computing power needed for inference tasks has grown by a factor of 2.5 annually.

The combined effect of these factors could boost the overall cognitive capacity of AI systems by more than 25 times each year. This is an astonishing change, comparable to a population increasing 25-fold every year. Furthermore, Forethought suggests that once AI research capabilities become equivalent to human research capabilities, AI research output could grow by at least 25 times annually. In other words, the research achievements of one year would be equivalent to 25 years’ worth after one year, and 625 years’ worth after two years—an extraordinary acceleration. Of course, this is a conjecture that does not account for “self-improving AI” with its own feedback loop. An unprecedented explosion of intelligence in human history is on the horizon.


However, we cannot entrust all problems to superintelligence. Therefore, the solutions available only at present will become difficult to implement as time passes, meaning we must act immediately.
Among the concrete measures proposed to prepare for AGI, one particularly interesting suggestion is to select and empower “responsible actors.” These “responsible actors” refer to individuals or groups with the following characteristics:
1. Individuals who possess a deep understanding of the potential risks and societal impacts of AI technology, enabling them to make ethical decisions.
2. Those who prioritize the long-term interests and safety of humanity over short-term gains or competitive advantage.
3. Individuals who work collaboratively with other researchers, companies, governments, and international organizations to pursue the safe and responsible development of AI technology.
4. Those who transparently disclose their research and decision-making processes and take responsibility for the outcomes.
“Responsible actors” bear a striking resemblance to the “Wallfacers” depicted in the novel. Both concepts refer to a small number of individuals granted special authority and responsibility in the face of a critical crisis that will determine humanity’s future.
In The Three-Body Problem, humanity faces the threat of invasion by the Trisolaran civilization—an alien civilization with technology far more advanced than Earth’s. The Trisolarans use a quantum computer called the “Sophon” to eavesdrop on all of Earth’s communications and even read human thoughts. In response, humanity establishes the “Wallfacer Project” and selects four Wallfacers. To evade Trisolaran surveillance, these Wallfacers must conceal their true intentions and plans, formulating strategies solely in their minds. They are granted enormous authority and resources to devise and execute plans to save humanity.
As AI technology accelerates, we are increasingly facing the possibility that imaginative concepts like the Wallfacers and the Dark Forest theory from Liu Cixin’s The Three-Body Problem may soon be discussed as real-world strategies. It is a stark reminder that we stand on the brink of an era of profound upheaval. Moreover, as the competition between the two leading nations intensifies in this era, one cannot help but wonder if what was once pure imagination might eventually become reality.
II. Agent War
1. China’s Manus AI
(1) The Second DeepSeek Shock?
In response to the closed-source giant OpenAI from the United States, a new player from China’s open-source camp has emerged. This is the company Monica, which has developed Manus AI—the world’s first fully autonomous AI agent. Already earning the nickname “the second DeepSeek,” it is generating significant hype and is expected to have a major impact on the U.S. AI industry.
Monica designed a browser plugin called “ChatGPT for Google” and quickly amassed 10 million users, gaining widespread recognition. The company was founded by Xiao Hong (肖弘), a 1992-born entrepreneur from Wuhan. The team, consisting of young talents including chief scientist Ji Yichao (季逸超), shocked Americans immediately upon releasing the preview of Manus on March 6. It seems that China is home to many brilliant young developers.
Even before its launch, Manus AI raised public expectations with somewhat exaggerated claims such as “potentially peeking into AGI,” “the world’s first true general-purpose AI agent,” and “Universal Hand.” Regardless, this promotional strategy resonated, attracting enormous global attention. Chinese media outlets such as Global Times and China Daily eagerly hailed it as “another Sputnik moment.”
Monica intentionally kept the waiting list for Manus AI under wraps, granting early access only to select influencers to create an aura of scarcity and anticipation. In other words, one needed to obtain an invitation code for the preview version in order to use Manus. These access codes were even reportedly traded on secondary platforms for as much as 10 million KRW. The company plans to open-source some models within this year.
Manus is acclaimed as a truly autonomous AI agent, capable of independently planning tasks, procuring necessary tools, and solving problems based on user instructions. Its core strength lies in its multi-agent system, which allows it to handle multiple tasks simultaneously.
Users interact with Manus via a text-based interface, enabling it to control the computer autonomously—remarkably similar to OpenAI’s Operator or Anthropic’s Computer Use, with the ability to manage files and execute programs on its own.
Moreover, several users—similar to those behind OpenAI’s Deep Research—have produced high-level reports and noted that Manus outperforms competitors in certain areas. Manus AI achieving the highest performance on the GAIA benchmark even suggests that it could pose a competitive threat to OpenAI.
However, Manus is the first to present results solely based on the GAIA benchmark. Instead of objectively evaluating performance through a variety of benchmarks, it emphasized only a specific benchmark result. This raises the possibility that Manus AI may be overly optimized for that benchmark, meaning it might not perform as well on a broader range of tasks. In particular, the fact that Yann LeCun, who has long been skeptical of large language models (LLMs), participated in the creation of the GAIA benchmark already casts doubt on the reliability of these benchmark results.
 performance across all three difficulty levels. Manus was evaluated using")
Nonetheless, there has already been a significant amount of viral buzz surrounding the use cases of Manus. Our team found that its ability to automatically generate research reports, websites, and more is truly remarkable.
In particular, its ability to replicate Apple’s official website—producing an almost identical webpage, complete with animations and nearly matching every element except for the images—was nothing short of mind-blowing.
Examples of Use Cases Possible with Manus AI
• Resume Review and Ranking: When provided with a ZIP file containing resumes from 20 CEO applicants, Manus autonomously searched the web, took notes, deeply analyzed each applicant, and ranked them according to specified criteria.
• Real Estate Research and Report Generation: Utilizing various filtering criteria.
• Stock Correlation Analysis, Visualization, and Website Deployment.
• Travel Insurance Comparison Analysis.
• B2B Lead Generation and Information Provision.
• Research and Analysis in Diverse Fields such as Biomedicine.
• Custom Software Creation: Designing the app architecture as desired by the user, drafting implementation guides, and even generating actual code.
• SEO Reporting: By simply providing a URL, Manus automatically analyzes a website and generates a comprehensive SEO report that identifies and suggests improvements to help the site rank better on search engines.
(2) The Dual Nature of Manus
Manus AI operates in its own cloud computing environment (Linux Ubuntu) via the command line. It breaks down user-requested tasks into multiple stages, records them as Markdown files, and utilizes external tools and services—such as Cloudflare Workers and Git repositories—to complete websites.
Although it is based on an open-source model, thanks to its astonishing agent capabilities, some companies have even decided to discontinue paying for SaaS services that cost around $6,000 per year and instead have Manus build their web applications directly.
In other words, Manus AI is significant because it empowers users to create software on their own, which could radically transform the existing SaaS market. It has the potential to change development paradigms and particularly impact the SaaS sector. A new era is approaching where individuals can build their own applications to enhance work efficiency across various fields such as finance, real estate, insurance, marketing, and research. Fundamentally, these agents are extremely helpful in automating repetitive tasks.
In light of Manus’s debut, many are exclaiming, “The world has changed,” and “It feels like we’re experiencing AGI.” Particularly if the official release is priced under $200, it could pose a serious threat to ChatGPT Pro subscriptions. This sentiment is especially negative for OpenAI, which is planning to launch an agent subscription model priced at over $2,000.
Even those who initially thought it was nothing more than vaporware later expressed that, after actual use, they were so astonished that they experienced an “existential crisis.” Its autonomy and intelligence in deconstructing tasks and independently searching for the necessary tools were highly praised. In particular, its ability to seek out resources and learn on its own—even in fields where hardly any reference materials exist—as well as its capability to apply that knowledge, was truly remarkable.
However, not all feedback was positive. What sounded particularly disappointing was that Manus is fundamentally based on Anthropic’s Claude 3.7 Sonnet model, a product of a U.S. company. In fact, Manus AI doesn’t emulate the Claude Code CLI (a tool that allows the Claude model to run in a terminal environment, i.e., a command-line interface); it merely calls the API to utilize the functionalities of Claude Code CLI. It isn’t imitating or mimicking—it’s simply leveraging Claude’s features. Manus AI only presents the results obtained from Claude Code CLI to the user in an appropriate format (e.g., as a website, text, or code). Moreover, since the American Claude model is blocked in China, the Manus AI website isn’t even accessible there. This implies that, despite being developed with the Chinese market in mind, Manus AI’s market accessibility is limited by its inherent technical constraints.
One user on X (formerly Twitter) released the runtime code extracted from Manus AI’s core sandbox—the remote environment in which Manus AI controls the web browser, interacts with websites, and performs tasks—and revealed that Manus is based on the Claude Sonnet model and comprises 29 tools. The implication was that it is not fundamentally a new technology, but rather a patchwork of existing ones. In fact, that same user even presented evidence showing that they could very easily replicate Manus’s code using the Claude Sonnet 3.7 model, suggesting that anyone could implement it with relative ease. This leak also exposed significant security vulnerabilities in Manus.
Furthermore, while Manus’s team claimed that they had post-trained the model based on the Claude Sonnet model, some analyses suggest that they merely used the Sonnet model as-is without any additional training. In other words, these observations lend some weight to the argument that Manus AI is merely a “wrapper.” Here, “wrapper” refers to a software component that utilizes existing technology (e.g., LLMs) to offer new functionalities or services.
Additionally, the distribution of invitation codes required to access Manus was also restricted. While this limitation could be due to server overload caused by its high popularity—its aggressive marketing likely attracted an overwhelming number of users—it might also indicate that the operational costs are extremely high from the outset. According to the AI developer community, the cost per task for Manus AI is estimated to be around $2. The high cost is primarily attributed to the underlying Claude 3.7 Sonnet model, which is inherently very expensive and comes with usage limitations. This restricts the number of tasks Manus AI can process simultaneously, increases the cost per task, and prolongs the time required to complete each task.

Therefore, I oppose simply joining the hype of a technology that promises to change the world. At the very least, DeepSeek was built on its own developed language model, offering low costs and broad accessibility, which attracted significant attention. In contrast, Manus AI is based on a third-party model (Claude) and comes with high costs and limited accessibility, making it inappropriate to call it the second DeepSeek moment.
Nevertheless, it shouldn’t be dismissed as entirely meaningless. After all, both Cursor and Perplexity are also “wrappers.” They provide services in a wrapper format without having their own models, yet they are valued as highly successful companies.
Manus’s success can be seen as a success at the level of application development rather than at the model-building level like DeepSeek. Success is success, and the fact that China has achieved it once again only makes it an even bigger issue.
III. U.S. Moat: Autonomous Driving Software
1. The Significance of Tesla FSD’s Entry into China
(1) The Autonomous Driving Market Will Become an Oligopoly
In various aspects—including AI accelerators and language models—China’s pursuit is remarkable, raising concerns that it might soon catch up. Conversely, what U.S. technologies does the American camp have that China cannot immediately replicate? Identifying companies with such a moat could serve as a guiding compass for AI investments.
Fundamentally, China has followed a pattern of protectionism regarding technological complexity. This pattern was evident in past industries such as smartphones, secondary batteries, and electric vehicles. During the technology development process, China would initially open its market to Western countries, allowing them to absorb and refine the technology; once alternatives became available, domestic companies would naturally be promoted. One can easily recall how, for nearly a decade, LG Chem was repeatedly excluded from the Chinese government’s EV battery subsidy lists—part of a policy designed to foster a domestic battery industry and based on the belief that even with its own value chain, a company could remain globally competitive.
Approximately three weeks ago, Tesla’s autonomous driving system, FSD, was partially launched in China. However, market interest has been surprisingly muted. Nevertheless, the fact that Chinese regulators approved it—and considering Tesla’s performance and economic standing—makes this move highly significant. It is possible that regulators, believing there is still much to learn from American companies regarding autonomous driving technology, acceded to Tesla’s request. Additionally, this could help improve public perception of autonomous driving technology and serve as a testing ground for emerging markets and industries. Of course, by giving Tesla some leeway and effectively using it as a social experiment, domestic companies will be encouraged to quickly imitate their methods and refine their own technologies.
In other words, there is still a gap in autonomous driving software, and Tesla has time on its side. Why is that? Autonomous driving models are far more complex than language models. First, driving scenarios are extremely intricate; second, the economic losses from accidents can be enormous, making safety requirements exceptionally strict. Autonomous driving represents the cutting edge of technology—the interface between artificial intelligence and the real world.
Customers who enjoy the benefits of convenient and flawless autonomous driving are unlikely to sacrifice safety by purchasing inferior products from other companies. This is why the CEO of Momenta, a leading Chinese autonomous driving firm, stated that “the global autonomous driving market will become an oligopoly.” In essence, while convenience is important, when it comes to life-critical technology, only a handful of companies with the highest performance will dominate the market. This forms the core of the competitive moat that Tesla is building with its FSD.
(2) Background of Tesla FSD’s Entry into China and Its Data Processing Strategy
For Tesla to operate FSD in China, local data collection is, unsurprisingly, key. Tesla’s vehicle systems begin data collection and validation in “shadow mode.” In this mode, while the FSD system tracks the decisions it would make during driving, it does not actually control the vehicle, thereby gathering crucial data for system validation.
Furthermore, Tesla is constructing data centers in China to localize data storage, with all data generated from vehicles sold in the Chinese mainland set to be stored within China. In other words, the entire “data closed loop” must remain on the mainland—a necessary measure to comply with China’s data sovereignty policies.
In fact, several years ago, Tesla set up a local operations team of about 20 people in China to facilitate FSD’s market penetration and even established data-labeling teams of hundreds to support FSD algorithm training. Data labeling is a critical process in developing autonomous driving systems, and Chinese labelers, with their understanding of local road conditions and traffic rules, can provide more accurate annotations.
However, even if Tesla secures the qualification to collect data in China, the need to conduct model training locally remains a significant bottleneck. To achieve FSD training efficiency comparable to that in the United States, China would need to build a supercomputing center similar to Dojo—a project that would require substantial development time and cost. In the first place, it is unlikely that China could import tens of thousands of GPUs. Nevertheless, a Dojo-level supercomputing center may not be necessary in China; Tesla’s U.S.-based supercomputer cluster, Cortex, can be used to create a baseline General World Model for FSD, which can then be fine-tuned using local Chinese data. This approach efficiently maintains fundamental driving intelligence while optimizing for China’s unique road conditions. Tesla has now demonstrated that this method is feasible.
2. The Emergence of the “Chinese FSD” and User Experience
(1) The Launch and Features of the “Chinese FSD”
On February 25, 2025, Tesla rolled out a software update for Chinese customers that is similar to its FSD functionality. Interestingly, in China, Tesla did not use the term “FSD” directly; instead, it opted for the somewhat cumbersome name “Autopilot Automatic Assisted Driving on Urban Roads.” This naming choice appears to be related to market strategies developed during the approval process with Chinese regulators.
However, while the three-letter acronym “FSD” does not appear anywhere on Tesla China’s official website, the described functionality is very similar to North American FSD. In fact, one Chinese Tesla owner recounted that a Tesla China customer service representative recently stated that the updated features could be understood as “FSD in China.” Therefore, for convenience, we will refer to the official name “Autopilot Automatic Assisted Driving on Urban Roads” as “Chinese FSD.”
The FSD version released in China appears to be v13.2.6, which is almost identical to the North American version v13.2.7. (Of course, the U.S. is currently rolling out v13.2.8 sequentially.) This shows that the technology Tesla is offering in the Chinese market is close to the latest version. Naturally, the version trained on Chinese road data might differ slightly from the U.S. version.
The Chinese version has been optimized for local roads and traffic regulations, but its training data level may be lower than that of U.S. FSD. These differences stem from variations in the quantity and quality of available training data, as well as differences in local traffic laws and driving culture. The key features of this Chinese update include:
1. Existing NOA (Navigate on Autopilot) Automatic Assisted Driving:
• The system drives in accordance with the road’s speed limits.
• When the user needs to pass through highway on/off ramps or during urban driving, the system guides the vehicle based on road signs and traffic lights.
• It also handles lane changes, left/right turns, and stops, automatically adjusting speed and lane positioning to choose the optimal path.
2. Driver-Facing Camera:
• This camera monitors the driver’s attention and issues warnings when necessary.
• The footage from the driver-facing camera is stored only within the vehicle, and Tesla does not have access to it, ensuring user privacy.
3. Map Version Update:
• The update applies version CN-2025.8-15218, which includes map data optimized for Chinese road conditions.
• It is integrated with 3D lane-level navigation (Baidu Maps).
(2) Pricing and Market Potential
Naturally, this update applies only to vehicles that have purchased the FSD software. The Chinese FSD is available for a one-time fee of RMB 64,000 (approximately $8,800). For reference, this is different from “Enhanced Autopilot (EAP, which is also available in Korea),” offered at half the price of FSD but with significantly limited functionality.
Moreover, the scope of Chinese FSD is currently quite restricted. It is only available on vehicles equipped with “HW 4.0” hardware, and FSD must be purchased as a one-time fee rather than via a subscription. Tesla China announced the HW 4.0 upgrade for the Model Y on February 1, 2024, through its official social media accounts (Weibo and WeChat).
In other words, the entire Model Y lineup released after that date is upgraded to HW 4.0, meaning that only these vehicles are capable of running Chinese FSD.

Based on data as of March 2024, if we estimate the cumulative sales of Tesla vehicles in China until January 2025 to be about 620,000 units, and assume that 20% of those owners—that is, roughly 120,000 people—purchase FSD at a price of 64,000 CNY, then the market size would be approximately 7.7 billion CNY (around 1.5 trillion KRW). This could provide Tesla with a significant additional revenue stream. Moreover, it is encouraging that deliveries of the new Tesla Model Y “Juniper” in China began on February 26, as customers buying new vehicles at this time are likely to also purchase the Chinese FSD.
More broadly, since 2020 Tesla has sold about 2.19 million vehicles in China, of which an estimated 1.6 million are equipped with HW 3.0. These vehicles represent a potential customer base, although applying FSD to HW 3.0 models may require additional time for optimization and rollout. If the Tesla autonomous driving team fails to implement FSD on HW 3.0 in the short term, a free hardware upgrade (replacing HW 3.0 with HW 4.0) might occur, just as it did in the U.S. Conservatively assuming a 10–15% adoption rate under such an upgrade, about 200,000 FSD users would prepay $8,800 each. This clearly demonstrates the economic potential of the FSD business in the Chinese market.
(3) Actual Performance and User Response of Chinese FSD
Once the Chinese version of FSD was released, many bloggers began live streaming its operation. They conducted “live broadcasts” to test how well the American-made autonomous driving system performs on Chinese roads. Notably, while many test videos from North America have been seen before, the fact that the Chinese test videos were all broadcast live adds to their credibility.
Chinese Tesla owners mostly set arbitrary destinations and activated FSD, and their overall reaction was one of surprise at the system’s performance, which exceeded expectations. They were impressed by its excellent basic driving ability, noting that FSD initially has no operational design domain (ODD) restrictions—in other words, it can handle roads it has never encountered before without issue.
Testers drove in various environments—including urban areas, narrow streets, markets, overpasses, underground parking lots, and even mountain roads—and even owners tested the system under severe weather conditions. Cases of “inoperability” or frequent accidents—predicted by some media—were rarely observed. The driving performance was remarkably human-like, and the overall route planning ability was rated as top-notch, providing evidence that Tesla FSD can function effectively even in China’s complex traffic environment.
Among the testing teams was one composed of experts who had firsthand experience with various Chinese autonomous driving systems from companies such as Huawei, RioTo, Xiaopeng, and BYD. Their first impression was that “compared to other Chinese autonomous driving systems, Tesla FSD drives much more like a human—it is smoother and exudes confidence.” Notably, even when it made mistakes such as taking the wrong route or missing a turning point, it demonstrated the ability to “self-correct.” In contrast, most other Chinese autonomous driving systems, including those from Huawei, tend to hesitate in such situations.
About five years ago, a Chinese autonomous driving company called Mometa—pioneering the end-to-end approach—explained that one of the main challenges in building such a system was “developing decision-making and planning capabilities.” Tesla FSD has demonstrated outstanding performance in this area, proving its technical superiority. Ultimately, the testers concluded that the Chinese FSD system drives more like a human than any system they had experienced so far, awarding it a 9 out of 10 in their evaluations.
That said, there were a total of four driver takeovers during the test drives. In three instances, FSD mistook bus-only lanes or bicycle lanes for regular driving lanes. The remaining instance occurred when a van suddenly merged, prompting the driver to take control to avoid a side collision.
Additionally, some Tesla owners reported that the Chinese FSD version still exhibits issues such as “running red lights, going straight through left-turn lanes, and mis-entering lanes.” However, problems like ignoring red lights are relatively easy to fix in AI model development through “verifiable rewards.” Therefore, with each subsequent update, the Chinese FSD is expected to gradually evolve into a more reliable driving system that better masters local driving rules.
3. “Everything Is a Computer”: The Competitive Moat Demonstrated by Tesla FSD’s Entry into China
(1) Technical Characteristics of the Chinese FSD and Tesla’s Methodology
Considering that FSD was trained not on local Chinese vehicle data but solely on publicly available videos, its performance is truly remarkable. It is almost unimaginable for an American—who has never been to China and is completely unfamiliar with local traffic rules or the driving habits of Chinese motorists—to drive as proficiently under congested conditions as FSD does. And yet, FSD has achieved that.
However, since the Chinese FSD has not yet been trained on an extensive volume of local road data, its performance might be comparable to that of “an American driver who has adapted to China for about a week.”
So how did the Tesla China team train FSD and acquire the necessary data? They utilized data collected by Tesla vehicles driving on specific roads in major Chinese cities, in addition to publicly available Chinese road and signage videos found on platforms such as YouTube.
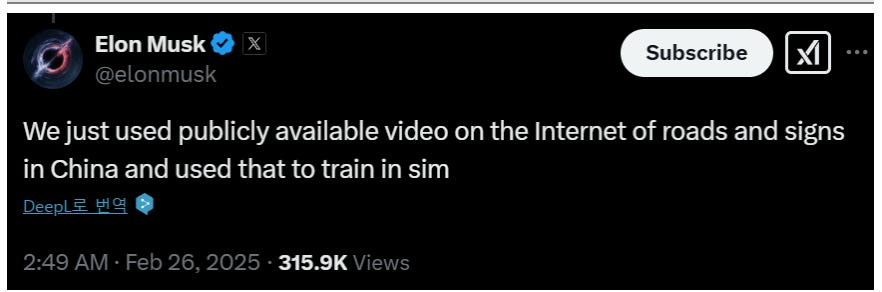
CEO Elon Musk directly stated, “We trained [our system] in a simulation environment using publicly available Chinese road and sign videos from the internet.” Essentially, this approach is similar to NVIDIA’s “synthetic data generation-based autonomous driving development” strategy. According to the method disclosed by Musk, it can be interpreted that they captured publicly available driving data from the internet, trained it in a simulation environment, and then used it to train an end-to-end model.
• Speculations on Tesla’s method of improving the FSD model by operating between China and the United States:
1. Initial Model Deployment (US → China):
The FSD V13 model (including weights) developed in the United States is sent to Chinese servers. In this process, to comply with China’s data regulations (which prohibit the export of raw data overseas), the model weights were likely transmitted in an encrypted form.
2. Fine-tuning with Local Chinese Data:
On Chinese servers, the model is fine-tuned using local driving data (such as camera footage and sensor data) collected from cities like Shanghai, Beijing, and Shenzhen. In this process, the model’s weights are updated and gradients are calculated.
3. Encryption and Transmission to Headquarters (China → US):
When the computed gradients from China are sent back to the US headquarters, homogeneous encryption is applied to ensure data security. Even if transmitted in an encrypted state, they can be immediately used in computations (for example, integrated into the global model).
In other words, the Chinese version of FSD is considered to be a model that takes the weights of the US FSD model and further fine-tunes them with limited local Chinese data and simulation data. The US FSD already possesses the “driving intelligence” that allows it to operate on general roads like a human driver. Therefore, with only a slight fine-tuning using local Chinese data, driving on Chinese roads becomes feasible. This approach essentially uses the weights of the US FSD model as the initial value and then focuses on additional training of components related to the Chinese road environment (such as signs, lane markings, and traffic flow) with China-specific data. Simply put, instead of training from scratch, the algorithm is optimized for China’s specific road conditions.
In fact, several individuals in contact with Tesla mentioned that in early February 2025, Tesla decided to relocate some of its US autonomous driving engineers to China to localize FSD and optimize the algorithms. Meanwhile, it is estimated that the computational power for additional training in China was obtained by renting a GPU cluster within China (comprising 1,024 NVIDIA H100 units), which is permitted under Chinese regulations.
Of course, the effectiveness of this method may be limited compared to the original FSD because, unlike the situation in the United States, there is a significant lack of local data. Elon Musk himself has acknowledged that the biggest challenge in deploying FSD in China is the shortage of data. Moreover, due to the substantial differences in both the quality and quantity between simulation data and actual data, it will be difficult to expect rapid update cycles and development progress similar to that of the US FSD for a considerable period. Additionally, while data can be collected, the inability to transmit it directly to the North American FSD team also hinders a fast iterative update cycle.
Nonetheless, now that the Chinese version of FSD has been deployed on vehicles of real users, it is expected that the system will gradually overcome these challenges through training with actual driving data.
(2) If End-to-End Methods Are Good, Why Can’t They Catch Up Quickly?
In the development of autonomous driving technology, there are two main approaches: the end-to-end method and the modular approach. The end-to-end method processes everything from input (sensor data) to output (vehicle control commands) using a single neural network. For example, in autonomous driving, the camera data is directly used to generate the vehicle’s steering, acceleration, and braking commands.
In contrast, the modular approach divides the autonomous driving process into several stages, with explicit rules and algorithms applied to each. For instance, there might be separate modules for lane detection, path planning, and vehicle control.
While the modular approach has its advantages (such as interpretability and flexibility), the benefits of the end-to-end approach are far more evident. Since the entire process is handled by one neural network, errors that occur in intermediate steps do not accumulate, and the entire system can be optimized all at once. Moreover, with massive amounts of data, it can learn complex patterns, thereby enabling more natural driving by learning specific driving patterns from the data.
However, mimicking this approach is not straightforward. The end-to-end method requires learning all input-output relationships, which demands an enormous amount of data. Simply mimicking human driving data is insufficient to adequately train the neural network. To overcome this, the amount of data must be truly vast; otherwise, a lack of data can severely degrade generalization performance.
For example, to learn the behavior of stopping at a red traffic light, the system must comprehensively understand factors such as “the color of the traffic light (red, green), the location of the traffic light, and the surrounding environment (roads, vehicles, pedestrians, etc.).” Humans naturally acquire this knowledge even before obtaining a driver’s license, but machines do not. One must recognize that trying to learn everything from scratch with an end-to-end approach, without any prior knowledge, requires an enormous volume of data.
Naturally, handling a complex task (like autonomous driving) with a single neural network makes the training process extremely complicated and time-consuming. This is precisely why not all autonomous driving companies can quickly transition to an end-to-end approach. Due to these practical challenges, even Andrej Karpathy (the former head of FSD) has stated that it is effective to first perform pre-training using intermediate representations (such as features and detectors) and then gradually move towards an end-to-end approach. In fact, companies that already have multiple neural network modules and have pre-trained specialized knowledge (such as traffic light recognition modules or object detection modules) may have a favorable starting point compared to building an end-to-end system from scratch.
(3) The Implications of Tesla’s Software Gap Advantage
The technical gap between Chinese companies that are now actively incorporating end-to-end methods and Tesla appears to be a complex issue that cannot be measured in “a few years.” The entry barrier for software algorithms is extremely high. Although Chinese companies like Huawei, Xiaopeng, and NIO have very talented AI experts, they have not yet fully grasped Tesla’s methodology.
In this regard, Tesla has adopted a strategy of no longer holding AI DAY events and not disclosing their architecture. While every company is aware that concepts—such as those revealed by Tesla at AI DAY 2021, including the end-to-end method like VLA (Vision-Language-Action) and concepts like OCC (Occupancy Network)—need to be utilized, executing the entire process “seamlessly” from perception to control remains a significant challenge. Although some open-source end-to-end architectures and codes exist, most are considered research demos and lack the practicality for use in real-world road environments. In other words, FSD possesses a complexity that makes it difficult to easily reverse-engineer or imitate.
Therefore, there have indeed been attempts to steal such software. In September 2020, a lawsuit was filed alleging that former Tesla employee Guangzhi Cao, who had worked in Tesla’s autonomous driving technology team, moved to Chinese company Xiaopeng and unlawfully took source code and confidential information related to autonomous driving technology. Since this incident, no company in China has dared to attempt poaching Tesla’s talent, and even informal contact in Silicon Valley has become difficult.
Furthermore, through this rollout, Tesla’s end-to-end and camera vision approach has been significantly validated, as FSD operates at a high level in China even without a large-scale local fleet or dedicated training. In contrast, most Chinese end-to-end teams tend to exhibit overfitting to specific cities, and a nationwide end-to-end system rollout remains a distant prospect. Additionally, adapting the system across different regions remains an even greater challenge.
Meanwhile, Liu Yilin, the head of autonomous driving products at Xiaopeng, provided a detailed expert evaluation of Tesla FSD’s entry into the Chinese market. He consistently stated that “although FSD has not fully adapted to the unique traffic environment of China, its fundamental technology is outstanding.” Liu Yilin pointed out that Tesla FSD shows shortcomings in certain aspects of China’s unique traffic conditions, such as bus-only lanes, waiting areas, and complex red traffic lights. However, the parts that do not adapt to local traffic infrastructure and traffic rules are relatively easier to resolve. Because it is a matter of “verifiable compensation,” these issues can be overcome through additional reinforcement learning based on local data (for example, learning in a 3D environment that simulates Chinese conditions with rules such as “deductions for crossing solid lines or for signal violations”).
At the same time, Liu Yilin summarized Tesla FSD’s excellent basic capabilities as follows:
• Static Detection: The detection of stationary objects is highly accurate and stable, operating reliably under various weather and traffic conditions.
• Dynamic Detection: It performs exceptionally well, with no errors in speed measurement or angle even after hours of driving.
• Responsiveness: Vehicle control is far superior to expectations, exhibiting human-like behavior and natural interactions with other vehicles.
Overall, Liu Yilin assessed that, in terms of actual experience in the Chinese market, Tesla FSD lags behind domestic Chinese automakers; however, its fundamental technology is “terrifyingly” advanced. Despite the lack of localization, its basic technology far outpaces that of domestic Chinese companies, clearly demonstrating Tesla’s technical superiority. This suggests that if Tesla obtains regulatory approval without the need for further software development, FSD could be deployed anywhere.
In other words, Tesla FSD’s entry into the Chinese market is an important case demonstrating the global applicability and methodological superiority of end-to-end technology—even with limited use of local data. Moreover, this approach represents a universal technology that can adapt to various environments and provides significant implications for the overall advancement of the robotics industry. For China, which is determined to excel in robotics development, this is an area that must be honed without exception.
Therefore, allowing the deployment of the Chinese version of FSD is a measure by Chinese regulatory authorities acknowledging the gap in end-to-end technology and quickly embracing Tesla’s approach. After all, the most valuable comparative advantage held by the United States is software. It has become increasingly likely that “everything in this world is a computer,” and that software will define the operation of these computers.
In that sense, aren’t we already living in a “Software-Defined World”?
In conclusion, it is hereby disclosed that this article is an English translation of a report by Korea’s Mirae Asset Securities.